
When Millions of People Google “File Unemployment”
Part 40 explores the use of a "recession anxiety indicator" as a trade signal

This is part 40 of my series — Building & Scaling Algorithmic Trading Strategies
This post explores alternative data — specifically using Google search behavior — as a leading economic indicator. The idea isn’t to replace quantitative signals but to supplement them with information that’s available before official statistics catch up.
Maybe eventually this will end up going to ChatGPT or Perplexity (or maybe Gemini), but for today we have Google search trends.
The Core Observation
When someone loses their job, they search Google. Not next week. Not when the Bureau of Labor Statistics publishes numbers. Right now.
This creates a measurable gap:
Data Source Timing
─────────────────────────────────────────────
Google Trends Real-time (weekly updates)
Initial Unemployment Claims 1 week lag
Monthly Unemployment Rate 1-2 week lag after month end
GDP 30 days after quarter end
Corporate Earnings 30-45 days after quarter endThe academic support for this is reasonably solid. Choi and Varian (2012) found Google search data predicts unemployment claims with a 1-2 week lead. Da, Engelberg, and Gao (2011) showed abnormal search volume correlates with abnormal stock returns.
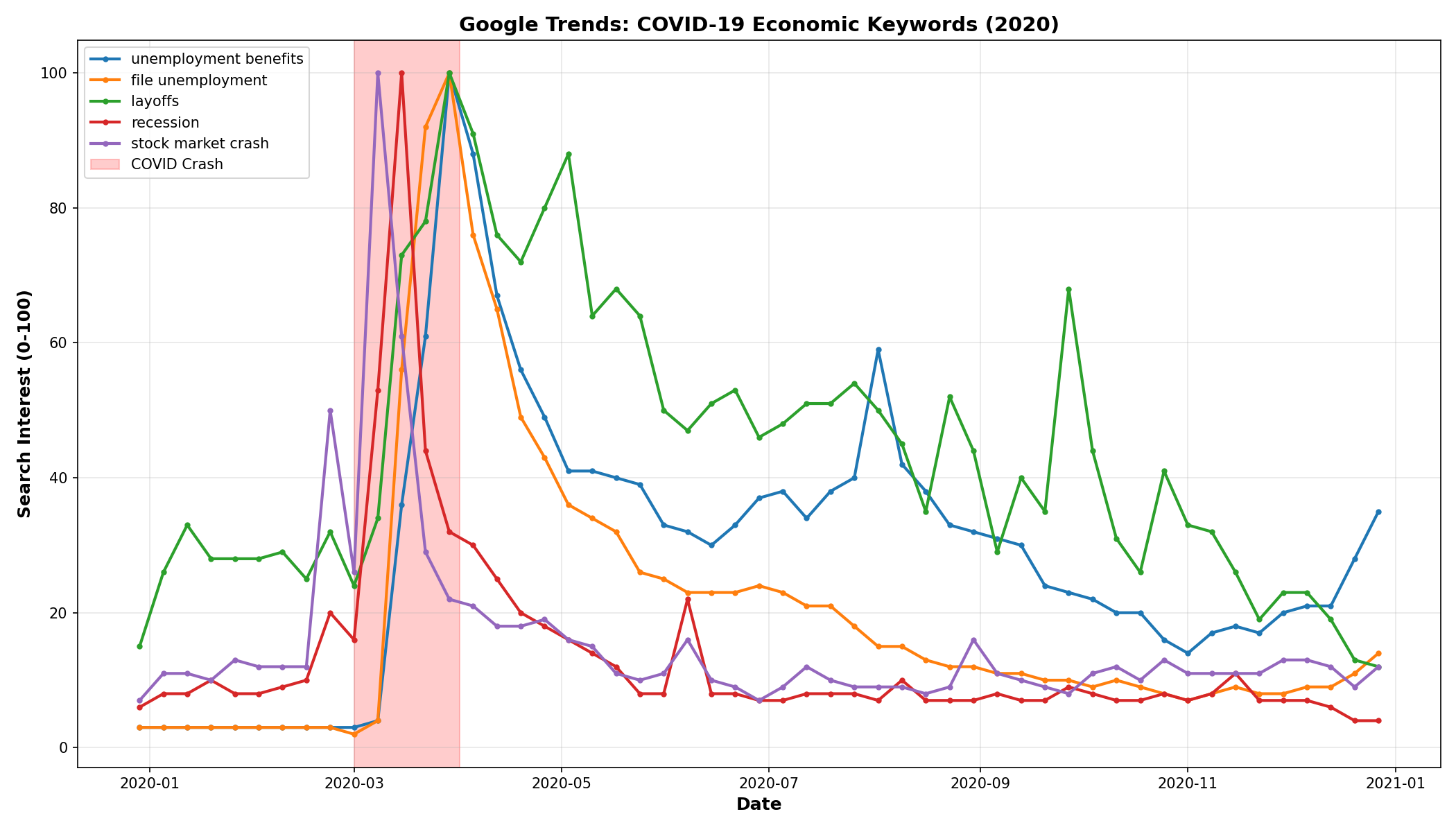
Building a Composite Index
The Recession Anxiety Index (RAI) aggregates 15 search terms across three categories:
Job Loss Terms (40% weight)
“unemployment benefits”
“file unemployment”
“indeed jobs”
“resume template”
“layoffs”
Financial Stress Terms (35% weight)
“food stamps”
“bankruptcy”
“debt relief”
“payday loans”
“food bank near me”
Economic Pessimism Terms (25% weight)
“recession”
“economic crisis”
“stock market crash”
“how to save money”
“budget tips”
The weighting rationale: job loss is the most immediate and actionable—people file within days. Financial stress terms like “bankruptcy” indicate severity but lag job loss by weeks. Pessimism terms are noisier (media-driven) but capture expectations.
The formula:
RAI = 0.40 × x̄(job loss) + 0.35 × x̄(financial stress) + 0.25 × x̄(pessimism)
Where each x̄ is the average of the normalized (0-100) search volumes for that category. A 4-week rolling average smooths out weekly noise.
The First Attempt: Zero Signals
I set up the thresholds based on intuition:
RAI Value Regime Position
───────────────────────────────────────────────
80+ Extreme Anxiety Contrarian Buy
60-80 High Anxiety Defensive
40-60 Moderate Neutral
30-40 Low Anxiety Long
0-30 Very Low Long (risky)Ran the backtest. Got an empty signals file.
No errors. The code completed successfully. Just... nothing. The portfolio CSV had data, but zero trading signals over 16 years.
The Debugging Journey
Attempt 1: Rate limiting? Google Trends throttles heavy API usage. Added exponential backoff, longer delays between requests. Still empty.
Attempt 2: Timezone mismatch? Found that SPY data was timezone-aware while signal timestamps were naive. Fixed the comparison logic. Still empty.
Attempt 3: Actually look at the data. Built a diagnostic script to print exact RAI values across the full period.
The maximum RAI from 2008-2024 was 23.6 and the threshold for “extreme anxiety” was 80. However, the signal never fired because it couldn’t fire.
Google Trends Normalization: The Hidden Problem
Here’s what I’d missed about how Google Trends works.
When you query a single keyword for a time period, Google returns values on a 0-100 scale where 100 = the highest search volume within that specific query period.
Query “unemployment benefits” for just 2020:
March 2020: 100 (the COVID spike was the peak)
June 2020: 95
December 2020: 30
Query “unemployment benefits” for 2008-2024:
Some month (maybe 2008, maybe 2020): 100
March 2020: ~23 (normalized down because 2008 might have been higher, or the algorithm distributes differently across longer periods)
June 2020: ~20
December 2020: ~8
The relative spike still exists. March 2020 is still elevated compared to December 2020. But the absolute scale shifts depending on your query window.
When I queried individual keywords for just the 2020 period, “unemployment benefits” hit 100 in March — exactly as expected. The data was correct. The thresholds were wrong.
The Fix: Percentile-Based Thresholds
Absolute thresholds don’t work with normalized data. The solution is to use the data’s own distribution:
Percentile RAI Value New Threshold
─────────────────────────────────────────────
50th (median) 11.8 Low
75th 13.7 Moderate
90th 16.0 High
95th 16.7 Extreme
99th 21.7 —
Maximum 23.6 —Updated thresholds:
Old New Meaning
─────────────────────────────────────
80 16.7 Extreme (95th percentile)
60 16.0 High (90th percentile)
40 13.7 Moderate (75th percentile)
30 11.8 Low (median)This is data-driven and adapts to whatever normalization Google applies. The 95th percentile means “top 5% of anxiety readings in the dataset”—that’s a meaningful threshold regardless of the absolute scale.
Real Data Results (2020-2024)
With calibrated thresholds, the backtest generated 23 signals across 5.9 years:
Metric SPY Buy & Hold RAI Strategy Difference
────────────────────────────────────────────────────────────────
Total Return 128.88% 161.40% +32.52%
Annualized 15.05% 17.67% +2.62%
Volatility 20.88% 16.93% -3.95%
Sharpe Ratio 0.72 1.04 +0.32
Max Drawdown -33.72% -24.50% +9.22%Signal distribution:
2020 COVID crash: 6 signals (May-October, RAI peaked at 25.4)
2022 inflation fears: 8 signals (June-October, Fed hiking aggressively)
Other periods: 9 signals scattered across 2020-2024
All signals are LONG—this is a contrarian buy-the-fear strategy. No shorts.
What the Numbers Mean
The outperformance comes from two sources:
Crisis timing. The strategy went long during COVID panic (May-October 2020) and held through recovery. It also caught the 2022 drawdown bottom.
Risk reduction. Sharpe of 1.04 vs 0.72 means 44% better risk-adjusted returns. Volatility dropped from 20.88% to 16.93%. Maximum drawdown improved by 9 percentage points.
Whether this holds out-of-sample is the real question. 23 signals over 5.9 years is roughly 4 per year—not a lot of data points.
Lessons for Alternative Data
The normalization problem generalizes beyond Google Trends:
Understand the data’s scaling before setting thresholds. Any data source that normalizes internally (sentiment scores, relative volume, z-scores) will have this issue.
Test individual components before composites. Querying “unemployment benefits” alone for 2020 showed the expected spike. The composite obscured the problem.
Use percentile-based thresholds for normalized data. The 95th percentile is meaningful across different scales. “Above 80” is not.
Silent failures are worse than loud failures. The code ran successfully. The CSV was just empty. No exception, no warning. Building diagnostic scripts upfront would have saved time.
Document the debugging journey. A year from now, I’ll forget why the thresholds are 16.7 instead of 80. The documentation exists for future-me.
Limitations
Sample size. 23 signals, n=2 major crises (2020, 2022). Not statistically robust.
Look-ahead bias in keywords. The terms were selected knowing they spiked in 2008 and 2020. Future crises may behave differently.
Google Trends methodology risk. If Google changes how they normalize or what data they expose, the strategy breaks.
Behavioral shift. ChatGPT, voice search, and TikTok may reduce traditional Google queries over time.
Execution psychology. Buying when RAI is at the 95th percentile means buying when everyone is terrified. Easy in a backtest, hard in reality.
What This Represents
The strategy outperformed SPY by 32.5% with better risk-adjusted returns over a nearly 6-year period. That’s notable but not conclusive.
The more useful output is the methodology: using freely available behavioral data, understanding its quirks, calibrating thresholds empirically, and documenting the debugging process.
Google Trends is free. The barrier to testing alternative data ideas is low. Even if this specific implementation doesn’t hold up over time, the approach—aggregating revealed preferences to anticipate official statistics — is worth understanding.
What’s next: extending the backtest to 2008-2012 (separate query to avoid cross-period normalization issues) and out-of-sample validation.
The information presented in Math & Markets is not investment or financial advice and should not be construed as such.