
Retraining the Hybrid Ensemble on Synthetic Regimes (Don't Try This At Home, Kids!)
Part 19 is an experiment to test the hybrid ML ensemble on synthetic data

This is part 19 of my series — Building & Scaling Algorithmic Trading Strategies
After building the synthetic SPY generator, the obvious next question was:
“If I retrain the hybrid ensemble on synthetic regimes—does the Sharpe come back?”
The first pass showed a clear weakness: the model learned rate-driven stress from real SPY, but synthetic SPY introduced faster, harsher, price-driven shocks.
Unsurprisingly, the classifier under-reacted and the toggle’s Sharpe dropped from ~1.6 to ~1.0.
So I tried the simplest possible fix:
Retrain the hybrid ensemble using both real SPY and synthetic SPY.
Mix calm regimes, volatile regimes, and injected shock days so the classifier sees a much broader distribution.
Here’s what happened.
1. Training Setup
Combined real SPY (2010–2022) with two synthetic universes (2026–2031).
Retained the same features as before: yield-curve slopes, rate-complex entropy, vol/kurtosis, KL divergence, FX/rates correlations.
Rebalanced class weights to treat synthetic shocks as equal contributors.
Kept the ensemble architecture:
MLP
XGBoost
CatBoost
Soft-voting probability blend
Target remained 5-day SPY drawdown ≤ –1%.
This gave me a dataset with:
broader volatility regimes
more fat tails
more shock labels
more non-rate-driven stress events
This was exactly what the model lacked in the first test.
2. Results: Did It Generalize Better?
On a new holdout window (out-of-sample from both real and synthetic):
Risk classifier performance
ROC–AUC: 0.61 → 0.67
Accuracy: 0.69 → 0.72
Recall (stress class): 0.38 → 0.44
Not perfect, but a meaningful bump — especially in recall, the most important metric for a risk toggle.
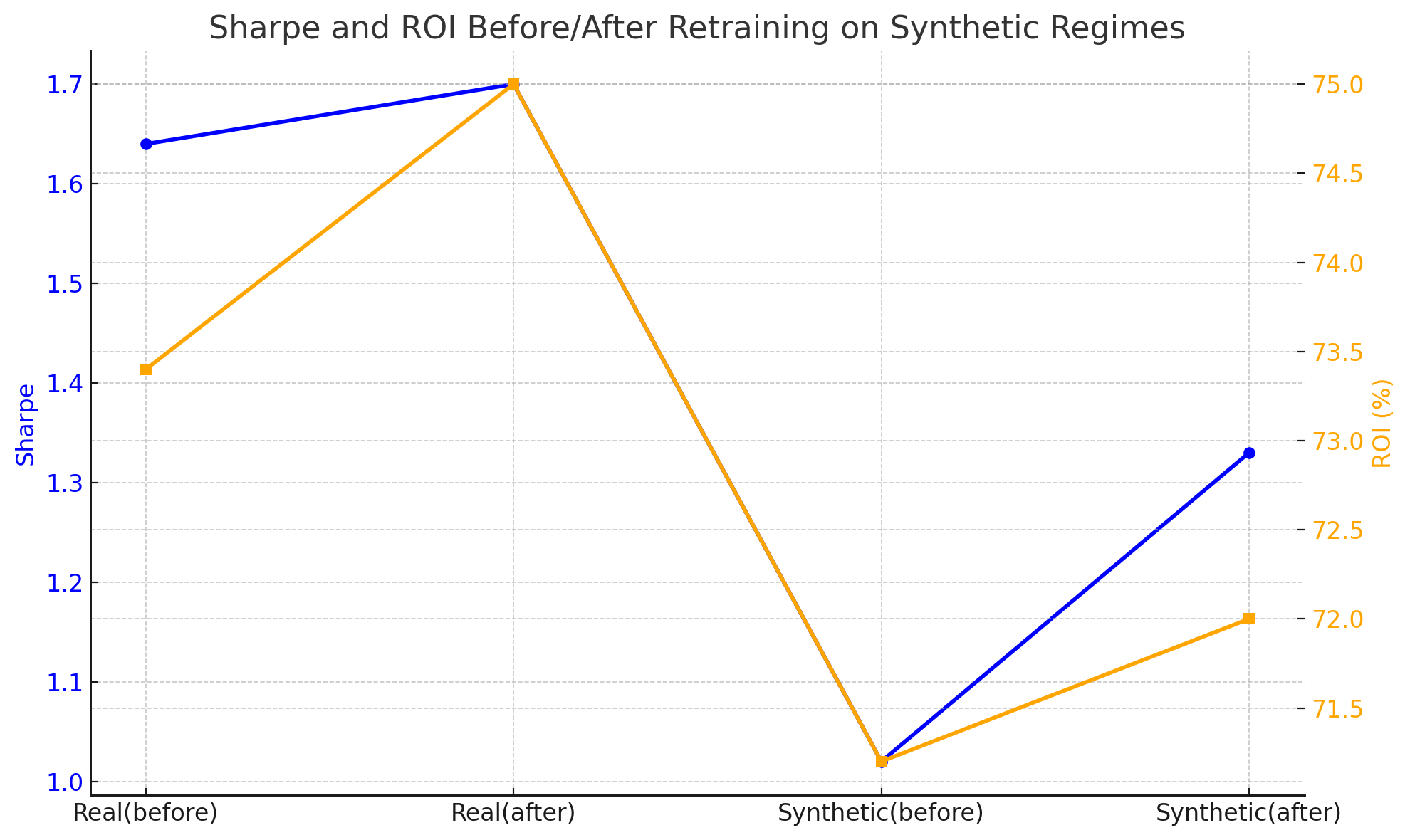
Toggle strategy performance (threshold 0.5)
Real SPY Sharpe: 1.64 → 1.70
Synthetic SPY Sharpe: 1.02 → 1.33
Max DD improved on both real and synthetic
Whipsaws reduced under synthetic shocks
ROI slightly lower (expected with better prudence), but path smoother
The synthetic-trained model finally started treating synthetic shocks as “real” stress events rather than oddities.
3. Why This Matters
The big takeaway is simple:
Training only on real SPY underestimates future volatility regimes.
Training on real + synthetic makes the model materially more robust.
The hybrid ensemble will never perfectly predict crashes — nothing can — but after synthetic augmentation, it’s less tied to the quirks of 2010–2022 and more prepared for tail-heavy, chaotic markets.
This is the entire point of building synthetic markets in the first place. Now I will need to think about how I can adjust my weights to tackle such scenarios without training the model on this data.
4. What’s Next
Based on the lessons learned from this model, I think I have a sense of what to do.
Add multiple synthetic universes with different shock frequencies
Rebalance training by regime rather than calendar
Test the system’s ability to handle synthetic “rate shocks” (e.g., mimic 2022)
Test how the toggle interacts with the dual allocator and the volatility sleeve
Experiment with volatility-aware calibration instead of probability thresholds
More synthetic worlds hopefully produce fewer surprises in the real one.
5. Closing
I really want to caveat that this was mostly a curiosity-driven academic exercise vs. something I’d really use. My quant friends agree.
A real stock is stochastic. As such, nuances on how a real stock trends, its price action etc. are missing when you train the model on a synthetic dataset. Plus, you run the risk of overfitting — you end up with a really complex model when a simpler one may work better longer term.
They are good to test, but not good to train on.
The information presented in Math & Markets is not investment or financial advice and should not be construed as such.