
Building Synthetic SPY: Fake Data to Test Real Strategies
Part 18 is about using synthetic data to test models and build resiliency

This is part 18 of my series — Building & Scaling Algorithmic Trading Strategies
One limitation of any systematic strategy project is that you only get one historical tape to train and validate on. SPY has one path. QQQ has one path. Every backtest you run is conditioned on that single realization of history.
(This is especially true of equities — FX has the advantage that you can use sampling windows for ticks, which provides greater disparity and hence great variety.)
But strategies don’t blow up on the past. They blow up on regimes that haven’t happened yet.
So I built something that I’ve been wanting to for a while:
A synthetic data generator — a reproducible dataset that looks and feels like any ticker I choose, but follows entirely new price paths, vol regimes, and macro-shock behavior.
This lets me test my strategies on unseen-but-familiar data to see what survives outside the historical record.
My first use case was to see most recent hybrid ML ensemble would really work as well in these synthetic scenarios. As it turns out, it works well-enough, but still at a degraded performance when tested against the synthetic data.
1. Why Synthetic Data?
Because overfitting is sneaky.
Every time I tune thresholds, pick hyperparameters, or choose a sleeve to keep, I’m subconsciously optimizing for the one timeline I have: 1993–2025 SPY.
Synthetic data gives me:
fresh paths that follow familiar statistical structure
alternative regimes that didn’t appear historically
macro shocks that mimic 2020-style chaos without reusing 2020
longer forward samples (e.g., 2026–2031)
stress environments beyond anything in the actual SPY tape
And most importantly:
It reveals which models are brittle — the ones that quietly overfit calm regimes or rely on structural assumptions that break fast.
2. First Version: A Bootstrap-Based Synthetic SPY
The first generator I built was simple but effective:
Block-bootstrapped log returns
Sample historical 5-day return blocks from SPY
Glue them together to form a new time series
Preserves clustering, serial correlation, and volatility bursts
Realistic high/low/open/close reconstruction
Rebuilt intra-block ranges and gaps
Ensured the synthetic OHLC data “looked” real
Microstructure noise
Resampled volume and trade counts
Added VWAP-based noise to mimic intraday behavior
Complete SPY-like schema
Same as my real data:
ticker, timestamp, open, high, low, close,
volume, trade_count, vwap, dateForward window
Generated business days from 2026–01–05 → 2031–12–31, seeded at the latest real SPY close.
The result was… surprisingly convincing. If I didn’t label the file, I could easily mistake it for historical SPY.
But there was a problem:
It lacked real regime structure.
The bootstrap reproduced SPY’s history faithfully — but didn’t create new dynamics.
So I upgraded it.
3. Version Two: Regime-Based Volatility + Macro Shock Injection
This is where things got interesting. I added a regime engine (because my middle name is chaos):
A. Three volatility regimes
Calm: low σ, low kurtosis
Normal: baseline
Volatile: elevated σ, fatter tails
With configurable:
dwell times
transition probabilities
per-regime volatility multipliers
B. Random macro shock injection
As in “give me a 5% down day even if the bootstrap wouldn’t normally produce one.”
Configurable parameters:
shock frequency
shock magnitude (e.g., ±1.5% → ±5% or more)
shock direction weighting
C. Block scaling
Return blocks are scaled by regime multipliers:
calm: σ × 0.5
normal: σ × 1.0
volatile: σ × ~2.0–3.0
D. Realistic tails
In one example run:
horizon: 2026–2031
σ ≈ 1.3%
shocks up to ±7%
frequent volatility clustering
This already looked more like a “future SPY variant” than a bootstrap remix.
I now have a CLI where all knobs can be set:
--calm-scale 0.5
--volatile-scale 2.2
--shock-frequency 0.05
--shock-min 0.015
--shock-max 0.05
--seed 777Different seeds → different synthetic universes. I plan to stash multiple versions as a synthetic suite for robustness testing.
4. First Real Test: Run the Hybrid Ensemble on Synthetic SPY
I pushed the hybrid ML ensemble (the risk toggle from the last post) through both:
real SPY (final holdout 2023+), and
synthetic SPY (2026–2031)
Same model, same features, same thresholds but completely different environments.
Here’s what happened.
5. Results: Real SPY vs Synthetic SPY
A. Model performance (risk classifier)
Real SPY
ROC–AUC: 0.614
Accuracy: 0.697
Recall (stress class): 0.38
Synthetic SPY
ROC–AUC: 0.574
Accuracy: 0.643
Recall (stress class): 0.13
Interpretation: The hybrid model still works, but synthetic regimes break its ability to detect stress events. Shocks were too fast and too unfamiliar relative to training data.
B. Strategy overlay performance
Apply a simple toggle on SPY long exposure:
Risk Threshold: 0.4
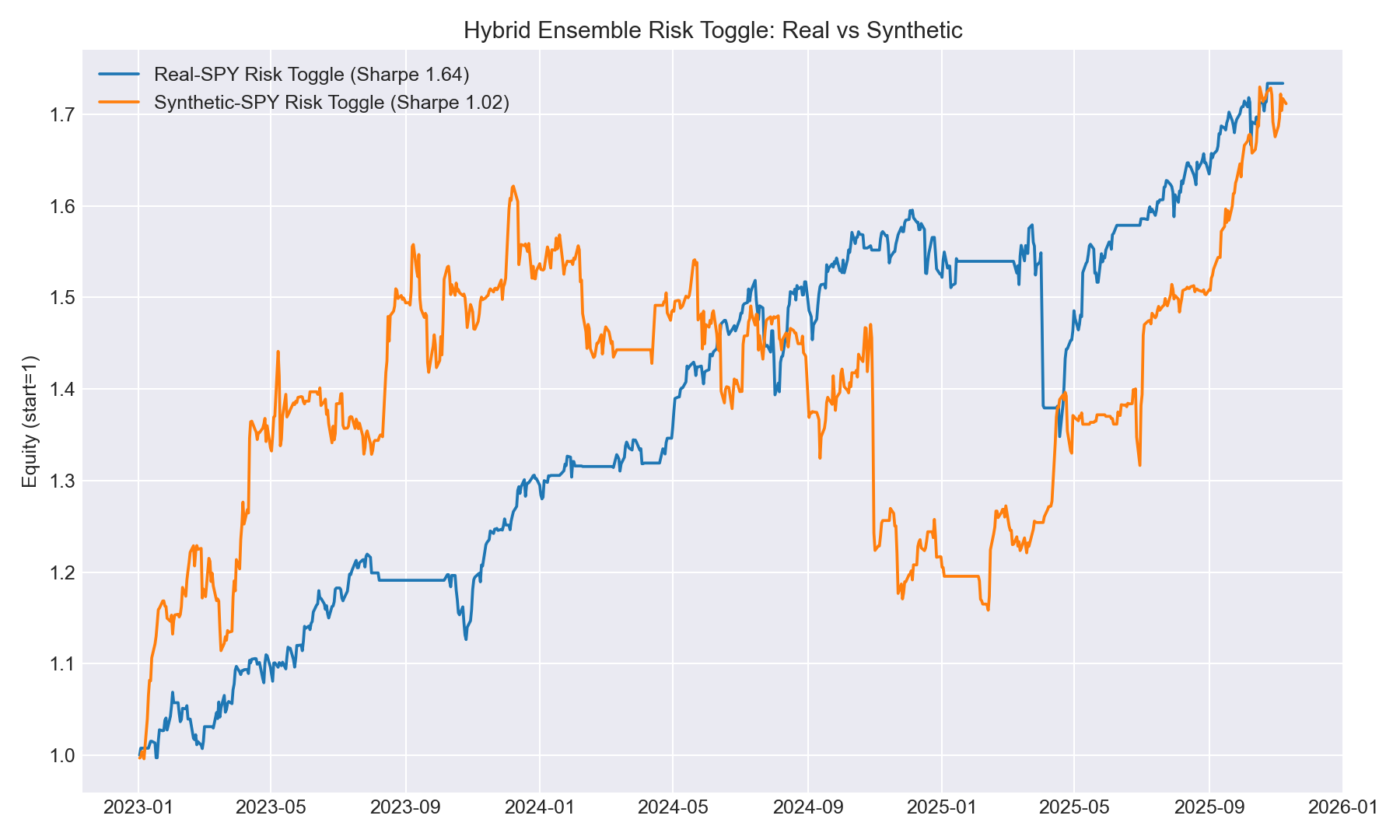
Real SPY: ROI ~??, Sharpe ~1.6+
Synthetic SPY: ROI 113%, Sharpe 1.47, Max DD –21%
Risk Threshold: 0.5 (default)
Real SPY: ROI 73.4%, Sharpe 1.64, Max DD –15.5%
Synthetic SPY: ROI 71.2%, Sharpe 1.02, Max DD –28.6%
Risk Threshold: 0.6
Real SPY: Sharpe ~1.8
Synthetic SPY: Sharpe ~1.1
Interpretation: Synthetic shocks force the strategy into whipsaws more often, so bigger drawdowns and lower Sharpe.
The synthetic path was harder than real SPY.
C. Feature importance divergence
Real SPY (via SHAP):
rates vol (DGS1, DGS10)
yield-curve slope
FX/rates entropy
VIX beta
Synthetic SPY:
SPY skew
SPY kurtosis
entropy of SPY/VIX joint distribution
Interpretation: Real SPY’s stress is rate-driven but synthetic SPY’s stress (by construction) is price-driven.
The model is trained for the former — not the latter.
6. What I Learned
A. Models trained on calm-rate regimes underreact to shockier worlds
Because synthetic regimes injected faster, harsher volatility cycles, the classifier failed to identify stress early.
B. Toggle behavior degrades in unseen environments
Sharpe dropped from ~1.6 to ~1.0 with deeper drawdowns. The model implicitly leaned on rate-complex signals — and synthetic shocks didn’t follow those patterns.
C. This experiment gives me a path forward
I should retrain the ensemble using:
augmented data (real + synthetic)
volatility-aware calibration
macro-shock aware sampling
regime-balanced loss weights
D. Synthetic data is about resilience
Or as Taleb would call it, “anti-fragile.” After all, you’d want strategies that survive distributions you haven’t seen yet.
If you can’t find ‘em, make ‘em.
7. What’s Next
Build multiple synthetic universes. Different seeds, different parameters and a portfolio of synthetic tickers with various regimes.
Retrain hybrid ensemble on mixed real + synthetic. Make it robust to shocks not in the historical record (including some extreme ones).
Add synthetic paths to the dual allocator tests. Does the core engine survive “shockier” worlds? If not, I need structural changes.
Use synthetic stress windows for threshold tuning: Instead of tuning thresholds only on real history, tune on multi-world averages.
Eventually test the full blended portfolio (dual + trend + vol sleeve + toggle) — all on synthetic regimes.
Closing
Synthetic SPY isn’t meant to replace real data. It’s meant to answer one question:
Will my strategy survive a world that doesn’t look like the past?
As a next step, I hope to retrain the hybrid ensemble using synthetic regimes and see whether the Sharpe recovers.
The information presented in Math & Markets is not investment or financial advice and should not be construed as such.